
- Gateways, Bridges, and Routers
- Gateway Protocols
- Routing Daemons
- Routing
- The IGP and EGPGateway Protocols
- Gateway-to-Gateway Protocol (GGP)
- The External Gateway Protocol (EGP)
- Neighbors and EGP
- EGP Messages
- Neighbor Acquisition Messages
- Neighbor Reachability Messages
- Poll Messages
- Update Messages
- Error Messages
- EGP to GGP Messages
- EGP State Variables and Timers
- Interior Gateway Protocols (IGP)
- The Routing Information Protocol (RIP)
- The HELLO Protocol
- The Open Shortest Path First (OSPF) Protocol
- Summary
- Q&A
- Quiz
— 5 —
Gateway and Routing Protocols
Gateway and Routing Protocols
TCP/IP functions perfectly well on a local area network, but its development was spurred by internetworks (more specifically by the Internet itself), so it seems logical that TCP/IP has an architecture that works well with internetwork operations. Today I examine these internetwork specifics in more detail by looking at the manner in which gateways transfer routing information between themselves.
The routing method used to send a message from its origin to destination is important, but the method by which the routing information is transferred depends on the role of the network gateways. There are special protocols developed specifically for different kinds of gateways, all of which function with TCP.
Gateways, Bridges, and Routers
To forward messages through networks, a machine's IP layer software compares the destination address of the message (contained in the Protocol Data Unit, or PDU) to the local machine's address. If the message is not for the local machine, the message is passed on to the next machine. Moving messages around small network is quite easy, but large networks and internetworks add to the complexity, requiring gateways, bridges, and routers, which try to establish the best method of moving the message to its destination.
Defining the meaning of these terms is relatively easy:
- A gateway is a device that performs routing functions, usually as a stand-alone device, that also can perform protocol translation from one network to another.
- A bridge is a network device that connects two or more networks that use the same protocol.
- A router is a network node that forwards datagrams around the network.
The gateway's protocol conversion capability is important (otherwise, the machine is no different from a bridge). Protocol conversion usually takes place in the lower layers, sometimes including the transport layer. Conversion can occur in several forms, such as when moving from a local area network format to Ethernet (in which case the format of the packet is changed) or from one proprietary file convention to another (in which case the file specifications are converted).
Bridges act as links between networks, which often have a bridge at either end of a dedicated communications line (such as a leased line) or through a packet system such as the Internet. There might be a conversion applied between bridges to increase the transmission speed. This requires both ends of the connection to understand a common protocol.
Routers operate at the network level, forwarding packets to their destination. Sometimes a protocol change can be performed by a router that has several delivery options available, such as Ethernet or serial lines.
A term you might occasionally see is brouter, a contraction of both bridge and router. As you might expect, brouters perform the functions of both a bridge and a router, although sometimes not all functions are provided. The term brouter is often applied for any device that performs some or all of the functions of both a bridge and a router.
A term in common use when dealing with routes is packet-switching. A packet-switched network is one in which all transfers are based on a self-contained packet of data (like that of TCP/IP's datagrams). There are also message-switched (self-contained complete messages, as with UNIX's UUCP system) and line-switched (fixed or dedicated connections) networks, but these are rarely used with TCP/IP. Packet-switched networks tend to be faster overall than message-switched networks, but they are also considerably more complex.
Gateway Protocols
Gateway protocols are used to exchange information with other gateways in a fast, reliable manner. Using gateway protocols, transmission time over large internetworks has been shown to increase, although there is considerable support for the idea of having only one protocol across the entire Internet (which would eliminate gateway protocols in favor of TCP/IP throughout).
The Internet provides for two types of gateways: core and non-core. All core gateways are administered by the Internet Network Operations Center (INOC). Non-core gateways are not administered by this central authority but by groups outside the Internet hierarchy (who might still be connected to the Internet but administer their own machines). Typically, corporations and educational institutions use non-core gateways.
The origin of core gateways arose from the ARPANET, where each node was under the control of the governing agency. ARPANET called them stub gateways, whereas any gateway not under direct control (non-core in Internet terms) was called a nonrouting gateway. The move to the Internet and its proliferation of gateways required the implementation of the Gateway-to-Gateway Protocol (GGP), which was used between core gateways. The GGP was usually used to spread information about the non-core gateways attached to each core gateway, enabling routing tables to be built.
As the Internet grew, it became impossible for any one gateway to hold a complete map of the entire internetwork. This was solved by having each gateway handle only a specific section of the internetwork, relying on neighboring gateways to know more about their own attached networks when a message was passed. One problem that frequently occurred was a lack of information for complete routing decisions, so default routes were used.
Earlier in this book, the term autonomous system was introduced. An autonomous system is one in which the structure of the network it is attached to is not visible to the rest of the internetwork. Usually, a gateway leads into the network, so all traffic for that network must go through the gateway, which hides the internal structure of the local network from the rest of the internetwork.
If the local network has more than one gateway and they can talk to each other, they are considered interior neighbors. (The term interior neighbor is sometimes applied to the machines within the network, too, not just the gateways.) If the gateways belong to different autonomous systems, they are exterior gateways. Thus, when default routes are required, it is up to the exterior gateways to route messages between autonomous systems. Interior gateways are used to transfer messages into an autonomous system.
Within a network, the method of transferring routing information between interior gateways is usually the Routing Information Protocol (RIP) or the less common HELLO protocol, both of which are Interior Gateway Protocols (IGPs). These protocols are designed specifically for interior neighbors. On the Internet, messages between two exterior gateways are through the Exterior Gateway Protocol (EGP). RIP, HELLO, and EGP all rely on a frequent (every thirty seconds) transfer of information between gateways to update routing tables.
The three gateway protocols are intertwined: EGP is used between gateways of autonomous systems, whereas the IGPs RIP and HELLO are used within the network itself. GGP is used between core gateways.
Why not use GGP for all internetwork communications, dropping the need for EGPs? The answer lies in the fact that core gateways that use GGP know about all the other core gateways on the internetwork. This simplifies their messaging and provides complete routing tables. However, core gateways usually lead into many complex networks of more autonomous networks, most of which the core gateways don't know about. However, the exterior gateways must know about all the networks directly connected to it, but not all the networks on the entire internetwork, so the routing tables and routing algorithms for a core and non-core gateway are different. This also means that messages can have different formats, because routing information for a non-core gateway has some connections that are hidden from other gateways.
It is possible for a large autonomous system to be composed of several subnetworks or areas, each of which communicates with the other areas through an IGP. Each subnetwork or area has a designated gateway, called a border gateway, or border router, to indicate that it is within an area. Border routers communicate with each other using IGP. A commonly encountered term is boundary gateway, which is the same as an exterior gateway or a path to another autonomous network. This is illustrated in Figure 5.1, which shows three subnetworks or areas that communicate with each other through boundary gateways or routers using IGP, and two exterior gateways (also called boundary gateways) that communicate with the rest of the internetwork using EGP.
Figure 5.1. Interior and exterior gateways.
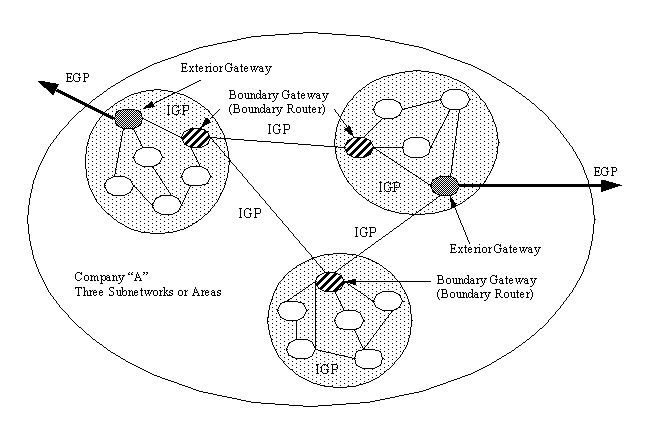{kind=link}
Routing Daemons
To handle the routing tables, most UNIX systems use a daemon called routed. A few systems run a daemon called gated. Both routed and gated can exchange RIP messages with other machines, updating their route tables as necessary. The gated program can also handle EGP and HELLO messages, updating tables for the internetwork. Both routed and gated can be managed by the system administrator to select favorable routes, or to tag a route as not reliable.
The configuration information for gated and routed is usually stored as files named gated.cfg, gated.conf, or gated.cf. Some systems specify gated information files for each protocol, resulting in the files gated.egp, gated.hello, and gated.rip. A sample configuration file for EGP used by the gated process is shown here:
# @(#)gated.egp 4.1 Lachman System V STREAMS TCP source
# sample EGP config file
traceoptions general kernel icmp egp protocol ;
autonomoussystem 519 ;
rip no;
egp yes {
group ASin 519 {
neighbor 128.212.64.1 ;
} ;
} ;
static {
default gateway 128.212.64.1 pref 100 ;
} ;
propagate proto egp as 519 {
proto rip gateway 128.212.64.1 {
announce 128.212 metric 2 ;
} ;
proto direct {
announce 128.212 metric 2 ;
} ;
} ;
propagate proto rip {
proto default {
announce 0.0.0.0 metric 1 ;
} ;
proto rip {
noannounce all ;
} ;
} ;
The code above shows a number of configuration details. It starts with a number of options and the switch that turns EGP on and sets the neighbor IP address. This is followed by code that defines the way EGP behaves. Most of the details are of little interest and are seldom (if ever) modified by a user. Instead, configuration routines tend to manage this file’s contents.
The UNIX system administrator also has a program called route that enables direct entry of routing table information. The information on a UNIX system regarding routing is usually stored in the file /etc/gateways.
It has become common practice to allow a default network Internet address of 0.0.0.0, which refers to a gateway on the network that should be capable of resolving an unknown address. (This is included in the previous sample configuration file as proto default.) The default route is used when the local machine cannot resolve the address properly. Because the routing tables on a gateway are usually more complete than those on a local machine, this helps send packets to their intended destination. If the default address gateway cannot resolve the address, an Internet Control Message Protocol (ICMP) error message is returned to the sender.
Routing
Routing refers to the transmission of a packet of information from one machine through another. Each machine that the packet enters analyzes the contents of the packet header and decides its action based on the information within the header. If the destination address of the packet matches the machine's address, the packet should be retained and processed by higher-level protocols. If the destination address doesn't match the machine's, the packet is forwarded further around the network. Forwarding can be to the destination machine itself, or to a gateway or bridge if the packet is to leave the local network.
Routing is a primary contributor to the complexity of packet-switched networks. It is necessary to account for an optimal path from source to destination machines, as well as to handle problems such as a heavy load on an intervening machine or the loss of a connection. The route details are contained in a routing table, and several sophisticated algorithms work with the routing table to develop an optimal route for a packet.
Creating a routing table and maintaining it with valid entries are important aspects of a protocol. Here are a few common methods of building a routing table:
- A fixed table is created with a map of the network, which must be modified and reread every time there is a physical change anywhere on the network.
- A dynamic table is used that evaluates traffic load and messages from other nodes to refine an internal table.
- A fixed central routing table is used that is loaded from the central repository by the network nodes at regular intervals or when needed.
Each method has advantages and disadvantages. The fixed table approach, whether located on each network node or downloaded at regular intervals from a centrally maintained fixed table, is inflexible and can't react to changes in the network topology quickly. The central table is better than the first option, simply because it is possible for an administrator to maintain the single table much more easily than a table on each node.
The dynamic table is the best for reacting to changes, although it does require better control, more complex software, and more network traffic. However, the advantages usually outweigh the disadvantages, and a dynamic table is the method most frequently used on the Internet.
Fewest-Hops Routing
Most networks and gateways to internetworks work on the assumption that the shortest route (in terms of machines traveled through) is the best way to route messages. Each machine that a message passes through is called a hop, so this routing method is known as fewest hops. Although experimentation has shown that the fewest-hops method is not necessarily the fastest method (because it doesn't take into account transmission speed between machines), it is one of the easiest routing methods to implement.
To provide fewest-hops routing, a table of the distance between any two machines is developed, or an algorithm is available to help calculate the number of hops required to reach a target machine. This is shown using the sample internetwork of gateways in Figure 5.2 and its corresponding table of distances between the gateways in the figure, which is shown in Table 5.1.
Figure 5.2. An internetwork of gateways.
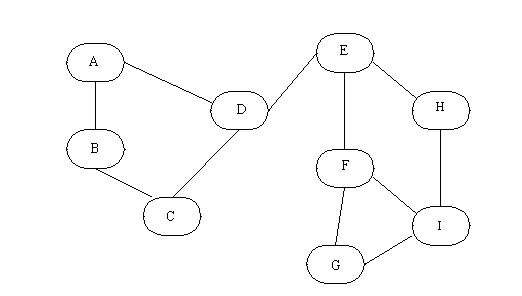{kind=link}
|
A |
B |
C |
D |
E |
F |
G |
H |
I | |
|
A
|
1
|
2
|
1
|
2
|
3
|
4
|
3
|
4
| |
|
B
|
1
|
1
|
2
|
3
|
4
|
5
|
4
|
5
| |
|
C
|
2
|
1
|
1
|
2
|
3
|
4
|
3
|
4
| |
|
D
|
1
|
2
|
1
|
1
|
2
|
3
|
2
|
3
| |
|
E
|
2
|
3
|
2
|
1
|
1
|
2
|
1
|
2
| |
|
F
|
3
|
4
|
3
|
2
|
1
|
|
1
|
2
|
1
|
|
G
|
4
|
5
|
4
|
3
|
2
|
1
|
2
|
1
| |
|
H
|
3
|
4
|
3
|
2
|
1
|
2
|
2
|
1
| |
|
I
|
4
|
5
|
4
|
3
|
2
|
1
|
1
|
1
|
When a message is to be routed using the fewest-hops approach, the table of distances is consulted, and the route with the fewest number of hops is selected. The message is then routed to the gateway that is closest to the destination network. When intermediate gateways receive the message, they perform the same type of table lookup and forward to the next gateway on the route.
There are several problems with the fewest-hops approach. If the tables of the gateways through which a message travels to its destination have different route information, it is conceivable that a message that left the source machine on the shortest route could end up following a more circuitous path because of differing tables in the intervening gateways. The fewest-hops method also doesn't account for transfer speed, line failures, or other factors that could affect the overall time to travel to the destination; it is merely concerned with the shortest apparent distance, assuming that all connections are equal. To accommodate these factors, another routing method must be used.
Type of Service Routing
This type of routing depends on the type of routing service available from gateway to gateway. This is called type of service (TOS) routing. It is also more formally called quality of service (QOS) by OSI. TOS includes consideration for the speed and reliability of connections, as well as security and route-specific factors.
To effect TOS routing, most systems use dynamic updating of tables that reflect traffic and link conditions. They also take into account current queue lengths at each gateway, because the fastest theoretical route might not matter if the message is backlogged in a queue. This information is obtained through the frequent transfer of status messages between gateways, especially when conditions deteriorate.
Dynamic updating of tables can have a disadvantage in that if tables are updated too frequently, a message might circulate through a section of the internetwork without proper routing to its destination, or proceed through a long and convoluted path. For this reason, dynamic updating occurs at regular but not too frequent intervals. To prevent stray datagrams from circulating on the internetwork too long, the Time to Live information in the IP message header is important.
The IP header's Time to Live (TTL) field is very important to dynamic gateway routing protocols, which is why it is a mandatory field. Without it, datagrams could circulate throughout the network indefinitely.
The dynamic nature of TOS routing can sometimes cause a message's fragments to be routed in different ways to a destination. For example, if a long message of 10 datagrams is being sent by one route, but the routing tables are changed during transmission to reflect a backlog, the remainder of the datagrams might be sent via an alternate route. This doesn't matter, of course, because the receiving machine reassembles the message in the proper order as the datagrams are received.
Updating Gateway Routing Information
A somewhat simplified example of a dynamic update is useful at this stage. The exact communications protocols between gateways are examined in more detail later today.
Assume that two autonomous networks are connected to each other at two locations, as shown in Figure 5.3, with connections to different autonomous networks at other locations. The A–C connection and the B–D connection can both be used for routing from within the networks, depending on which is the optimal path. Gateway C has a copy of gateway A's routing table, and vice versa. Gateways B and D each have copies of the other's routing tables, as well. These copies are transmitted at intervals so the gateways can maintain an up-to-date picture of the connections available through the other gateway. The gateways use EGP to send the messages. (They would use GGP if they were core gateways.)
Figure 5.3. Two interconnected networks.
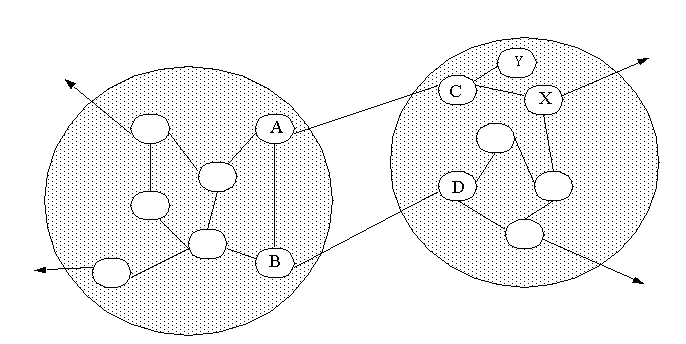{kind=link}
Suppose that a gateway link within one of the networks was broken due to a machine or connection failure, such as that between gateway C and machine X in Figure 5.3. Gateway C would find out about the problem through an IGP message and update its routing table to reflect the break, usually by putting the largest legal value for routing length in that entry. (Remember that IGP is a general term for any internal network protocol for gateway communications, such as RIP or HELLO.) Gateway C transfers its new copy of the routing table to gateway A.
Routing a message to machine Y would now be impossible through the C–X connection. However, because gateway A has the routing information from C, and it exchanges routing information with gateway B, which also exchanges with gateway D, any message passing through either D or B for machine Y could be rerouted up through gateway A, then C, and finally to Y. An EGP message between B–D and A–C would indicate that the new route costs less than the maximum value assigned going through C–X (which is broken), so the round-about transfer through the four gateways can be used.
EGP messages between gateways are usually sent whenever a connection problem exists and the routing information is set to its maximum (worst) value, or when a better connection alternative has been discovered for some reason. This can be because of an update from a remote gateway's routing table, or the addition of new connections, machines, or networks to the system. Whichever happens, an EGP message informs all the connected gateways of the changes.
The IGP and EGPGateway Protocols
Gateways need to know what is happening to the rest of the network in order to route datagrams properly and efficiently. This includes not only routing information but also the characteristics of subnetworks. For example, if one gateway is particularly slow but is the only access method to a subnetwork, other gateways on the network can tailor the traffic to suit.
A GGP is used to exchange routing information between devices. It is important not to confuse routing information, which contains addresses, topology, and details on routing delays, with the algorithms used to make routing information. Usually the routing algorithms are fixed within a gateway and not modified. Of course, as the routing information changes, the algorithm adapts the chosen routes to reflect the new information.
GGPs are primarily for autonomous (self-complete) networks. An autonomous system uses gateways that are connected in one large network, such as one might find in a large corporation. Two kinds of gateways must be considered in an autonomous network. The gateways between smaller subnetworks help tie the small systems into the larger corporate network, but the gateways for each subnetwork are usually under the control of one system (usually in the IS department). These gateways are considered autonomous because the connections between gateways are constant and seldom change. These gateways communicate through an IGP.
Large internetworks like the Internet are not as static as corporate systems. Gateways can change constantly as the subsidiary networks make changes, and the communications routes between gateways are more subject to change, too. For widely spread companies, there might be gateways spread throughout the country (or the world) that are all part of the same corporate network but use the Internet to communicate. The communications between these gateways are slightly different than when they are all physically connected together. These gateways communicate through an EGP.
There are fewer rules governing IGPs than EGPs simply because the IGP can handle custom-developed applications and protocols within its local network. When the Internet is used for gateway-to-gateway communications, the messages must conform to the internetwork standards. Also, when connecting two subnetworks, it is possible to send only one message to the subnetwork gateway through EGP, which can then be duplicated, modified, and propagated to all gateways on the internal system using IGP. EGP has formalized rules governing its use.
Gateway-to-Gateway Protocol (GGP)
GGP is used for communications between core gateways. A recent improvement of the protocol, called SPREAD, is starting to be used but is not yet as common as GGP. Even if GGP is phased out in favor of SPREAD, it is a useful illustration of gateway-to-gateway protocols.
GGP is a vector-distance protocol, meaning that messages tend to specify a destination (vector) and the distance to that destination. Vector-distance protocols are also called Bellman-Ford protocols, after the researchers who first published the idea. For a vector-distance protocol to be effective, a gateway must have complete information about all the gateways on the internetwork; otherwise, computing a distance with a fewest-hops type of protocol cannot succeed.
You might recall from earlier today that core gateways have complete information about all other core gateways, so a vector-distance protocol works. Non-core gateways don't have a complete internetwork map, so GGP-type messages are not useful.
A gateway establishes its connections to other gateways by sending out messages, waiting for replies, and then building a table. This is initially accomplished when a gateway is installed and has no routing information at all. This aspect of communications is not defined within GGP but relies on network-specific messages. Once the initial table has been defined, GGP is used for all messages.
Connectivity with another gateway on the Internet is determined using the K-out-of-N method. In this procedure, a gateway sends an echo message to another gateway and waits for a reply. It repeats this every fifteen seconds. According to the Internet standards, if the gateway does not receive three (K) replies out of four (N) requests, the other gateway is considered down, or unusable, and routing messages are not sent to that gateway. This process can be repeated at regular intervals.
If a down gateway becomes active again, the Internet standards require two out of four echo messages to be acknowledged. This is called J-out-of-M, where J is two and M is four. The Internet-assigned values for J, K, M, and N can be changed for autonomous networks, but the standard defines the values for use on the Internet itself.
Each message between gateways has a sequence number that is incremented with each transmitted message. Each gateway tracks its own sequence number for sending to every other gateway it is connected to, as well as the incoming sequence numbers from that gateway. They are not necessarily the same, because more messages might flow one way than the other, although usually each message should have an acknowledgment or reply of some type.
Sequence numbers have important meanings for the messages and are not just for the sake of keeping an incremental count of the traffic volume. When a gateway receives a message from another gateway, it compares the sequence number in that message to the last received sequence number in its internal tables. If the latest message has a higher sequence number than the last message received, the gateway accepts the message and updates its sequence number to the latest received value. If the number was less than the last received sequence number, the message is considered old and is ignored, with an error message containing the just-received message sent back. This process is shown in Figure 5.4.
Figure 5.4. Processing sequence numbers in GGP.
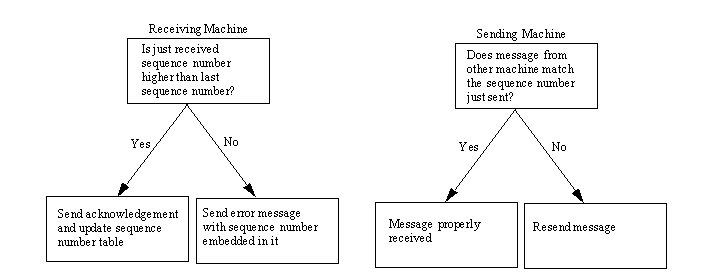{kind=link}
The receiving gateway acknowledges the received message by sending a return message that contains the sequence number of the just-received message. The other gateway compares that number with the number of its last sent message, and if they are the same, the gateway knows that the message was properly received. If the numbers do not match, the gateway knows an error occurred and transmits the message again.
When a message is ignored by the recipient gateway, the sending gateway receives a message with the sequence number of the ignored message. It can then determine which messages were skipped and adjust itself accordingly, resending messages that need to be sent.
The GGP message format is shown in Figure 5.5. After it is constructed, it is encapsulated into an IP datagram that includes source and target addresses. The first field is a message type, which is set to a value of 12 for routing information. The sequence number was discussed earlier and provides an incremental counter for each message. The Update field is set to a value of 0 unless the sending gateway wants a routing update for the provided destination address, in which case it is set to a value of 1. The Number of Distances field holds the number of groups of addresses contained in the current message.
Figure 5.5. The GGP message format.
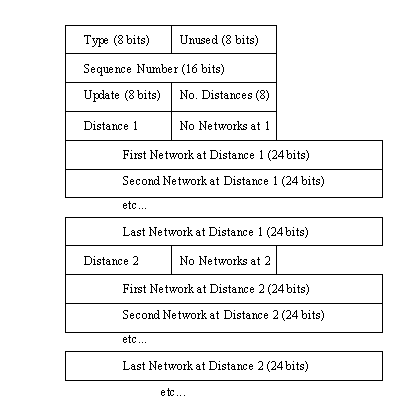{kind=link}
For each distance group in the message, a distance value and the number of networks that can be reached at that distance are provided, followed by all the network address identifications. According to the GGP standard, not all the distances need to be reported, but the more information supplied, the more useful the message is to each gateway.
GGP does not deal with full Internet addresses specifically, so the host portion of the address does not necessarily have to be included in the address, although the network address is always provided. This can result in different lengths of addresses in the identification field (8, 16, or 24 bits, depending on the type of address).
Three other formats are used with GGP messages, as shown in Figure 5.6. The acknowledgment message uses the Type field to indicate whether the message is a positive acknowledgment (type is set to 2) or a negative acknowledgment (type is set to 10) . The sequence number, as mentioned earlier today, is used to identify the message to which the acknowledgment applies.
Figure 5.6. Other GGP message formats.
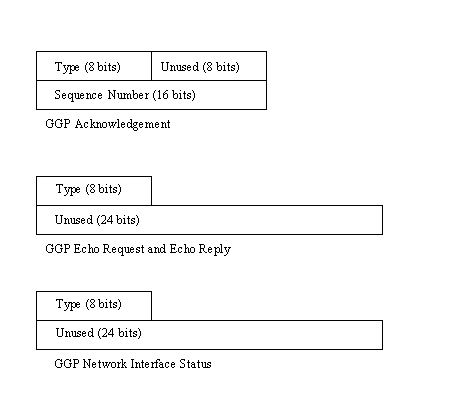{kind=link}
The echo request and echo reply formats are passed between gateways to inform the gateways of status changes and to ensure the gateway is up. An echo request has the Type field set to the value 8, whereas an echo reply has the Type field set to a value of 0. Because the address of the sending gateway is embedded in the IP header, it is not duplicated in the GGP message. The remaining 24 bits of the message are unused.
The network interface status message is used by a gateway to ensure that it is able to send and receive messages properly. This type of message can be sent to the originating gateway itself, with the type field set to a value of 9 and the IP address in the header set to the network interface's address.
The External Gateway Protocol (EGP)
As mentioned earlier, an EGP is used to transfer information between non-core neighboring gateways. Non-core gateways contain complete details about their immediate neighbors and the machines attached to them, but they lack information about the rest of the network. Core gateways know about all the other core gateways but often lack the details of the machines beyond a gateway.
EGP is usually restricted to information within the gateway's autonomous system. This prevents too much information from passing through the networks, especially when most of the information that relates to external autonomous systems would be unusable to another gateway. EGP therefore imposes restrictions on the gateways about the machines EGP passes routing information about.
Neighbors and EGP
Because EGP was developed to enable remote systems to exchange routing information and status messages, the protocol is heavily based in requests or commands followed by replies. The four EGP commands and their possible responses are shown in Table 5.2.
|
Command Name |
Command Description |
Response Name |
Response Description |
|
Request
|
Request that a neighbor become a gateway
|
Confirm/Refuse
|
Agree or refuse the request
|
|
Cease
|
Request the termination of a neighbor
|
Cease-Ack
|
Agree to termination
|
|
Hello
|
Request confirmation of routing to neighbor (neighbor reachability)
|
IHU
|
Confirms the routing
|
|
Poll
|
Request that the neighbor provide network information (network reachability)
|
Update
|
Provides network information |
To understand Table 5.2 properly, you must understand the concept of neighbor to an internetwork. Gateways are neighbors if they share the same subnetwork. They might be gateways to the same network (such as the Internet) or work with different networks. When the two want to exchange information, they must first establish communications between each other; the two gateways are essentially agreeing to exchange routing information. This process is called neighbor acquisition.
Neighbor doesn't mean the networks have to be next to each other. They are connected by a gateway, but the networks can be on different continents. The term neighbor has to do with connections, not geography.
The process of becoming neighbors is formal, because one gateway might not want to become a neighbor at that particular time (for any number of reasons, but usually because the gateway is busy). It begins with a Request, which is followed by either an acceptance (Confirm) or refusal (Refuse) from the second machine. If the two gateways are neighbors, either can break the relationship with a Cease message.
After two gateways become neighbors, they assure each other that they are still in contact by occasionally sending a Hello message, to which the second gateway responds with an IHU (I Heard You) message as soon as possible. These Hello/IHU messages can be sent at any time. With several gateways involved on a network, the number of Hello messages can become appreciable as the gateways continue to remain in touch. This process is called neighbor reachability.
The other message pair sent by EGP is network reachability, in which case one gateway sends a Poll message and expects an Update message in response. The response contains a list of networks that can be reached through that gateway, with a number representing the number of hops that must be made to reach the networks. By assembling the Update messages from different neighbors, a gateway can decide the best route to send a datagram.
Finally, an error message is returned whenever the gateway cannot understand an incoming EGP message.
EGP Messages
The layout of the different messages used by EGP are shown in Figure 5.7. The fields have the following meanings:
- The Version field holds the EGP version number of the sending machine (the current version is 2).
- The Type field identifies the type of EGP messages. There are ten message types in EGP.
- The Code field contains a value that identifies the subtype of the message.
- The Status field is used with the Type and Code fields to reflect the current status of the gateway's state.
- The Checksum is calculated for the EGP message in the same manner as other TCP/IP headers.
- The System Number is an identification of the autonomous system that the sending gateway belongs to.
- The Sequence Number of the message is an incrementing counter for each message, also used to identify a reply to a previous message.
Figure 5.7. EGP message format.
{kind=link}
The Reason field of the Error message can contain one of the following integers:
0—Unspecified error
1—Bad EGP header
2—Bad EGP data field
3—Reachability information not available
4—Excessive polling
5—No response received to a poll
Through a combination of the message Type, Code, and Status fields, the purpose and meaning of the EGP message can be more accurately determined. Table 5.3 shows all codes and status values.
|
Description |
Code |
Description |
Status |
Description | |
|
1
|
Update
|
0
|
0
|
Indeterminate
| |
|
1
|
Up
| ||||
|
2
|
Down
| ||||
|
128
|
Unsolicited
| ||||
|
2
|
Poll
|
0
|
0
|
Indeterminate
| |
|
1
|
Up
| ||||
|
2
|
Down
| ||||
|
3
|
Neighbor Acquisition
|
0
|
Request
|
0
|
Not specified
|
|
1
|
Confirm
|
1
|
Active mode
| ||
|
2
|
Refuse
|
2
|
Passive mode
| ||
|
3
|
Cease
|
3
|
Insufficient Resources
| ||
|
4
|
Cease-Ack
|
4
|
Prohibited
| ||
|
5
|
Shutting Down
| ||||
|
6
|
Parameter Problem
| ||||
|
7
|
Protocol Violation
| ||||
|
5
|
Neighbor Reachability
|
0
|
Hello
|
0
|
Indeterminate
|
|
1
|
I Heard You
|
1
|
Up
| ||
|
2
|
Down
| ||||
|
8
|
Error
|
0
|
0
|
Indeterminate
| |
|
1
|
Up
| ||||
|
2
|
Down
| ||||
|
128
|
Unsolicited |
The Status field can indicate whether a gateway is up or down. In the down state, the gateway does not perform any routing. The Neighbor Acquisition status indicator can show whether the machine is active or passive. When passive, the gateway does not generate any Hello commands, but it responds to them. At least one neighbor has to be in the active state to issue the Hellos.
When a list of networks and their distances must be added to an EGP header, it is done in the format shown in Figure 5.8. The number of distances in the list is specified, followed by entries with the same format giving the distance (number of hops) to the gateway, the number of networks that can be reached through that gateway, and the network addresses. The number of internal and external gateways in the EGP header tells the gateway how many entries are in the list.
Figure 5.8. Routing information in an EGP header.
{kind=link}
Using EGP, gateways can update each other and keep their routing tables current. A similar scheme is used for IGP, although the messages can be custom-designed by the network manager and application development team because they are not transmitted over the Internet.
Neighbor Acquisition Messages
A Neighbor Acquisition message (Request, Confirm, and Refuse Acquisition message types) is sent when a neighbor is being checked for acquisition. The same message format is used whether the particular message is a request, a confirmation, or a refusal.
The type is set to a value of 3 to indicate that the message is a neighbor acquisition, and the Code field provides the details as to the type of Acquisition message, as shown in Table 5.4.
|
Code |
Description |
|
0
|
Request Acquisition
|
|
1
|
Confirm Acquisition
|
|
2
|
Refuse Acquisition
|
|
3
|
Cease
|
|
4
|
Cease Acknowledgment |
The Status field in the Acquisition message header is set to one of eight possible values and is used to provide further information about the request. The valid Status field values are shown in Table 5.5.
|
Status |
Description |
|
0
|
Unspecified; used when no other code is applicable
|
|
1
|
Active; indicates an active status mode
|
|
2
|
Passive; indicates a passive status mode
|
|
3
|
Insufficient resources available
|
|
4
|
Administratively prohibited
|
|
5
|
Going down either because of operator intervention or expiration of the t3 timer
|
|
6
|
Parameter error with incoming message
|
|
7
|
Protocol violation in incoming message or response message is incompatible with current machine state |
The EGP Neighbor Acquisition message adds two new fields to the basic EGP message header. The 16-bit Hello Interval field specifies the minimum interval between Hello command pollings, in seconds. The 16-bit Poll Interval field specifies the minimum interval between Poll command pollings, again in seconds.
Neighbor Reachability Messages
The Neighbor Reachability messages are used to ensure that a neighbor that was previously acquired is still active and communicating. No extra fields are added to the basic EGP message format shown in Figure 5.7.
The Type field is set to a value of 5, but the Code field has a value of either 0 for a Hello message or 1 for an IHU (I Heard You) response. The Status field can have one of three values, shown in Table 5.6.
|
Status |
Description |
|
0
|
Indeterminate; used when no other code is applicable
|
|
1
|
Neighbor is in an up state
|
|
2
|
Neighbor is in a down state |
Poll Messages
The Poll messages are used to request network reachability information. An extra two fields are added to the basic EGP message format, which are a 16-bit field reserved for future use and a 32-bit IP Source Network field.
The Poll messages have the Type field set to a value of 2 and the Code field set to a value of 0. The Status field is set to one of the same three values used in the Reachability message, shown in Table 5.6.
The 16-bit Reserved field attached to the end of the basic EGP message format is ignored in the current versions of EGP. A 32-bit IP Source Network field is used to specify the IP address of the network about which the gateway is requesting reachability information.
Update Messages
Update messages are sent as a reply to a Poll message and provide information about network reachability. The format of the Update message is shown in Figure 5.9 and is similar to the GGP format discussed earlier.
Figure 5.9. EGP Update message format.
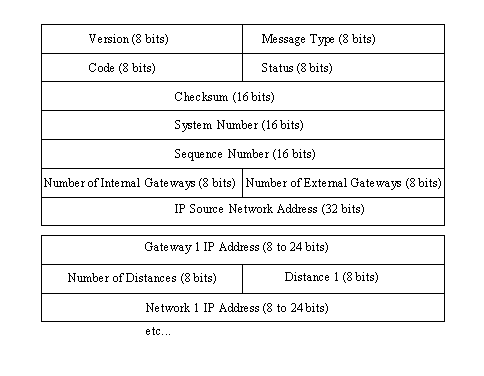{kind=link}
The Type of an Update message is set to 1, and the Code is set to 0. The Status field is set to one of the values shown in Table 5.7. (The values are the same as those for Reachability and Poll messages except for the addition of one value.)
|
Status |
Description |
|
0
|
Indeterminate; used when no other code is applicable
|
|
1
|
Neighbor is in an up state
|
|
2
|
Neighbor is in a down state
|
|
128
|
Unsolicited message |
After the familiar EGP header information are three new fields. The number of internal gateways and number of external gateways fields specify the number of interior and exterior gateways that are reported in the message, respectively. The IP Source Network Address field contains the IP address of the network to which the information relates.
Following the three gateway summaries and the usual header are one or more sets of information about each gateway the current system is sending information about. These are called gateway blocks because each set of fields refers to one gateway. The first field is the gateway's IP address. The Number of Distances field provides the number of distances that are reported in the gateway block and the number of networks that lie at that distance. Then, for each distance specified, the IP network address of each network is provided. Many blocks of gateway information can be provided in an Update message.
Error Messages
The final EGP message is the Error message, which has the same format as the basic EGP message, with two fields attached. The 16-bit first field is reserved. Following this is a 96-bit field that contains the first 96 bits of the message that generated the error.
EGP to GGP Messages
Core gateways use GGP, and non-core gateways use EGP, so there must be some method for the two to communicate with each other to find out about hidden machines and networks that lie beyond their routing tables. This can be shown by Figure 5.10, where gateway A is a core gateway leading from the internetwork to a network that has non-core gateways leading to two other networks. Another gateway on the internetwork does not have information about the networks and gateways past the core gateway, unless specifically updated about them through a request.
Figure 5.10. Core and non-core gateways.
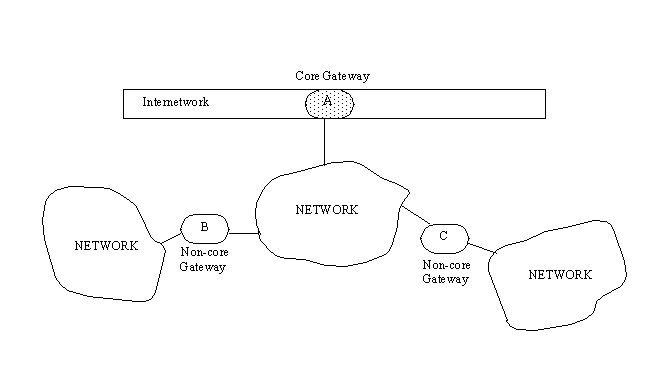{kind=link}
The Internet uses a method by which any autonomous (non-core) gateway can send reachability information to other systems, which must also go to at least one core gateway. If there is a larger autonomous network, one gateway usually assumes the responsibility for handling this reachability information. In Figure 5.10, gateway A is responsible for sending information about the three networks that lead from it, as well as the two non-core gateways.
EGPs use a polling process to keep themselves aware of their neighbors as they become active or go down, and to exchange routing and status information with all their neighbors. EGP is also a state-driven protocol, meaning that it depends on a state table containing values that reflect gateway conditions and a set of operations that must be performed when a state table entry changes. There are five states, as shown in Table 5.8.
|
State |
Description |
|
0
|
Idle
|
|
1
|
Acquisition
|
|
2
|
Down
|
|
3
|
Up
|
|
4
|
Cease |
The meanings of each of these EGP states follow:
- An idle state means the gateway is not involved in any activity and has no resources allocated to it. It usually responds to a message to initialize itself but ignores all other messages unless it switches to either the down or acquisition states.
- An acquisition state enables a gateway to transmit messages but not act as a full messaging gateway. It can receive messages and change to either down or idle states.
- The down state is when the gateway is not operational as far as polling operations are concerned. Messages are neither received nor generated.
- The up state is used whenever a gateway is processing and responding to all EGP messages it receives and can transmit messages.
- A gateway is in cease state when the gateway ceases all updating operations but can still send and receive Cease and Cease Acknowledgment messages.
All EGP messages fall into one of three categories: commands, responses, or indications. A command usually requires an action to be performed, whereas a response is a reply to a command to perform some action. An indication shows current status. Command-response signals are shown in Table 5.9.
|
Command |
Response |
|
Request
|
Confirm
|
|
Refuse
|
none
|
|
Error
|
none
|
|
Cease
|
Cease Ack
|
|
Error
|
none
|
|
Hello
|
IHU (I Heard You)
|
|
Error
|
none
|
|
Poll
|
Update
|
|
Error
|
none |
EGP State Variables and Timers
As mentioned earlier, EGP is state-driven, which means that the current state of the system depends on the last message received, or the condition of one of the software timers. EGP maintains a state table with several parameters that can be referenced to determine actions. These values usually refer to delays between sending or receiving messages of a specific type. In addition, a set of timers is maintained for ensuring that intervals between events are reasonable. The EGP parameters and timers are shown in Table 5.10, using the names employed in the RFC that defines EGP.
|
Name |
Description |
|
M
|
Hello polling mode.
|
|
P1
|
Minimum interval acceptable between successive received Hello commands. Default is 30 seconds.
|
|
P2
|
Minimum interval acceptable between successive received Poll commands. Default is 120 seconds.
|
|
P3
|
Interval between Request or Cease command retransmissions. Default is 30 seconds.
|
|
P4
|
Interval during which the state variables are maintained without receiving an incoming message when in the up or down state. Default is one hour.
|
|
P5
|
Interval during which the state variables are maintained without receiving an incoming message when in the cease or acquisition state. Default is 2 minutes.
|
|
R
|
Receive sequence number.
|
|
S
|
Send sequence number.
|
|
T1
|
Interval between Hello command retransmissions.
|
|
T2
|
Interval between Poll command retransmissions.
|
|
T3
|
Interval during which reachability attempts are counted.
|
|
t1
|
Retransmission timer for Request, Hello, and Cease messages.
|
|
t2
|
Retransmission timer for Poll messages.
|
|
t3
|
Abort timer. |
Many of the state parameters are set during the initial establishment of a connection between neighbors. The exceptions are the P1 through P5 values, which are established by the host system and are not modified by the neighbors. The send sequence number is determined only after a message has been received from the other gateway.
A full discussion of the changes between EGP states and the events that occur when a state change occurs is longer than this book and is not of relevance to this level of discussion. Therefore, the original RFC should be consulted for full state condition information. It is useful at this point simply to be aware of the state-driven nature of EGP and to understand that the state can be changed by a message reception, lack of a reply to a message, or expiration of a timer.
Interior Gateway Protocols (IGP)
There are several IGPs in use, none of which have proven themselves dominant. Usually, the choice of an IGP is made on the basis of network architecture and suitability to the network's software requirements. Earlier today, RIP and HELLO were mentioned. Both are examples of IGPs. Together with a third protocol called Open Shortest Path First (OSPF), these IGPs are now examined in more detail.
Both RIP and HELLO calculate distances to a destination, and their messages contain both a machine identifier and the distance to that machine. In general, messages tend to be long, because they contain many entries for a routing table. Both protocols are constantly connecting between neighbors to ensure that the machines are active and communicating, which can cause network traffic to build.
The Routing Information Protocol (RIP)
The Routing Information Protocol found wide use as part of the University of California at Berkeley's LAN software installations. Originally developed from two routing protocols created at Xerox's Palo Alto Research Center, RIP became part of UCB's BSD UNIX release, from which it became widely accepted. Since then, many versions of RIP have been produced, to the point where most UNIX vendors have their own enhanced RIP products. The basics are now defined by an Internet RFC.
RIP uses a broadcast technology (showing its LAN heritage). This means that the gateways broadcast their routing tables to other gateways on the network at regular intervals. This is also one of RIP's downfalls, because the increased network traffic and inefficient messaging can slow networks down compared to other IGPs. RIP tends to obtain information about all destinations in the autonomous system to which the gateways belong. Like GGP, RIP is a vector-distance system, sending a network address and distance to the address in its messages.
A machine in a RIP-based network can be either active or passive. If it is active, it sends its routing tables to other machines. Most gateways are active devices. A passive machine does not send its routing tables but can send and receive messages that affect its routing table. Most user-oriented machines (such as PCs and workstations) are passive devices. RIP employs the User Datagram Protocol (UDP) for messaging, employing port number 520 to identify messages as originating with RIP.
The format of the RIP messages is shown in Figure 5.11. The message header is composed of three fields for the command (set to 1 if a request and 2 if a response), the version number of the RIP protocol, and an unused reserved field. The rest of the message contains address information. Each set begins with an identifier of the family protocol used (RIP is not specifically for the Internet's protocols, but if used on the Internet this value is set to 2) and a set of network IDs. There are 96 bits available for the network address, of which only a maximum of 32 are necessary for an Internet address. The last field is a metric value that usually identifies the number of hops to the network.
Figure 5.11. RIP message format.
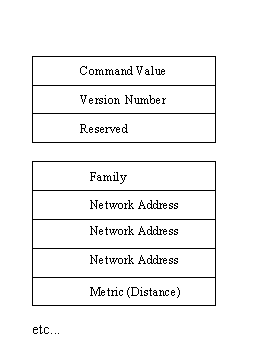{kind=link}
A Request message is usually sent to another gateway when a routing update is needed. When a request is received, the system examines the message to check each network address provided. If its routing table has a distance to that network address, it is placed in the corresponding metric field in the response. If there is no entry in the local routing table, no value is returned. One convention in common use is to code the family as 1 and the metric field as 16. When this is received, the message is interpreted as a request for the entire routing table.
Each RIP-based machine in the network maintains a routing table, with an entry for each machine that it can communicate with. The table has entries for the target's IP address, its distance, the IP address of the next gateway in the path to the target, a flag to show whether the route has recently been updated, and a set of timers that control the route. The distance is expressed as a number of hops required to reach the target and has a value from 1 to 15. If the target is unreachable, a value of 16 is set.
The timers involved with RIP are devoted to each possible route in the routing table. A time-out timer is set when the route is initialized and each time the route is updated. If the timer expires (the default setting is 180 seconds) before another update, the route is considered unreachable. A second timer, called the garbage-collection timer, takes over after the time-out timer and marks when the route is completely expunged from the routing table. The garbage-collection timer has a default value of 120 seconds. If a request for a routing update is received after the time-out timer has expired but before the garbage-collection timer has expired, the entry for that gateway is sent but with the maximum value for the route value. After the garbage-collection timer has expired, the route is not sent at all.
A response timer triggers a set of messages every 30 seconds to all neighboring machines, in an attempt to update routing tables. These messages are composed of the machine's IP address and the distance to the recipient machine.
The HELLO Protocol
The HELLO protocol is used often, especially where TCP/IP installations are involved. It is different from RIP in that HELLO uses time instead of distance as a routing factor. This requires the network of machines to have reasonably accurate timing, which is synchronized with each machine. For this reason, the HELLO protocol depends on clock synchronization messages.
The format of a HELLO message is shown in Figure 5.12. The primary header fields are as follows:
- A checksum of the entire message
- The current date of the sending machine
- The current time of the sending machine
- A timestamp used to calculate round-trip delays
- An offset that points to the following entries
- The number of hosts that follow as a list
Figure 5.12. HELLO message format.
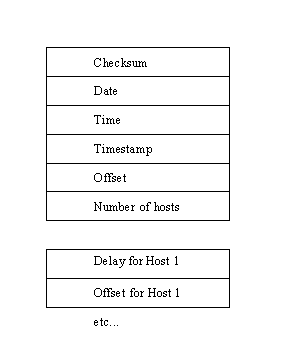{kind=link}
Following the header are several entries with a delay estimate to the machine and an offset, which is an estimate of the difference between the sending and receiving clocks. The offsets are important because HELLO is a time-critical protocol, so the offset enables correction between times on different machines.
The timestamp on messages is used by machines that the message passes through to calculate delays in the network. In this manner, a routing table based on realistic delivery times can be constructed.
The Open Shortest Path First (OSPF) Protocol
The Open Shortest Path First protocol was developed by the Internet Engineering Task Force, with the hope that it would become the dominant protocol within the Internet. In many ways, the name "shortest path" is inaccurate in describing this protocol's routing process (both RIP and HELLO use a shortest path method—RIP based on distance and HELLO on time). A better description for the system would be "optimum path," in which several criteria are evaluated to determine the best route to a destination. The HELLO protocol is used for passing state information between gateways and for passing basic messages, whereas the Internet Protocol (IP) is used for the network layer.
OSPF uses the destination address and type of service (TOS) information in an IP datagram header to develop a route. From a routing table that contains information about the topology of the network, an OSPF gateway (more formally called a router in the RFC, although both terms are interchangeable) determines the shortest path using cost metrics, which factor in route speed, traffic, reliability, security, and several other aspects of the connection. Whenever communications must leave an autonomous network, OSPF calls this external routing. The information required for an external route can be derived from both OSPF and EGP.
There are two types of external routing with OSPF. A Type 1 route involves the same calculations for the external route as for the internal. In other words, the OSPF algorithms are applied to both the external and internal routes. A Type 2 route uses the OSPF system only to calculate a route to the gateway of the destination system, ignoring any routes of the remote autonomous system. This has an advantage in that it can be independent of the protocol used in the destination network, which eliminates a need to convert metrics.
OSPF enables a large autonomous network to be divided into smaller areas, each with its own gateway and routing algorithms. Movement between the areas is over a backbone, or the parts of the network that route messages between areas. Care must be taken to avoid confusing OSPF's areas and backbone terminology with those of the Internet, which are similar but do not mean precisely the same thing. OSPF defines several types of routers or gateways:
- An Internal Router is one for which all connections belong to the same area, or one in which only backbone connections are made.
- A Border Router is a router that does not satisfy the description of an Internal Router (it has connections outside an area).
- A Backbone Router has an interface to the backbone.
- A Boundary Router is a gateway that has a connection to another autonomous system.
OSPF is designed to enable gateways to send messages to each other about internetwork connections. These routing messages are called advertisements, which are sent through HELLO update messages. Four types of advertisements are used in OSPF:
- A Router Links advertisement provides information on a local router's (gateway) connections in an area. This message is broadcast throughout the network.
- A Network Links advertisement provides a list of routers that are connected to a network. It is also broadcast throughout the network.
- A Summary Links advertisement contains information about routes outside the area. It is sent by border routers to their entire area.
- An Autonomous System Extended Links advertisement contains information on routes in external autonomous systems. It is used by boundary routers but covers the entire system.
OSPF maintains several tables for determining routes, including the protocol data table (the high-level protocol in use in the autonomous system), the area data table or backbone data table (which describes the area), the interface data table (information on the router-to-network connections), the neighbor data table (information on the router-to-router connections), and a routing data table (which contains the route information for messages). Each table has a structure of its own, the details of which are not needed for this level of discussion. Interested readers are referred to the RFC for complete specifications.
OSPF Packets
As mentioned earlier, OSPF uses IP for the network layer. The OSPF specifications provide for two reserved multicast addresses: one for all routers that support OSPF (224.0.0.5) and one for a designated router and a backup router (224.0.0.6). The IP protocol number 89 is reserved for OSPF. When IP sends an OSPF message, it uses the protocol number and a Type of Service (TOS) field value of 0. Usually, the IP precedence field is set higher than normal IP messages, also.
OSPF uses two header formats. The primary OSPF message header format is shown in Figure 5.13. Note that the fields are not shown in their scale lengths in this figure for illustrative purposes. The Version Number field identifies the version of the OSPF protocol in use (currently version 1). The Type field identifies the type of message and might contain a value from those shown in Table 5.11.
Figure 5.13. OSPF message header format.
{kind=link}
|
Type |
Description |
|
1
|
Hello
|
|
2
|
Database description
|
|
3
|
Link state request
|
|
4
|
Link state update
|
|
5
|
Link state acknowledgment |
The Packet Length field contains the length of the message, including the header. The Router ID is the identification of the sending machine, and the Area ID identifies the area the sending machine is in. The Checksum field uses the same algorithm as IP to verify the entire message, including the header.
The Authentication Type (AUType) field identifies the type of authentication to be used. There are currently only two values for this field: 0 for no authentication, and 1 for a password. The Authentication field contains the value that is used to authenticate the message, if applicable.
The second header format used by OSPF is for Link State advertisements only; it is shown in Figure 5.14. All Link State advertisements use this format, which identifies each advertisement to all routers. This header mirrors the topologic table.
Figure 5.14. OSPF Link State advertisement header format.
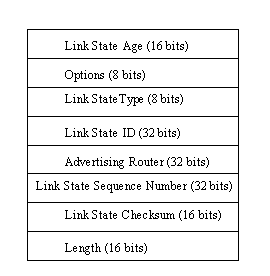{kind=link}
The Link State Age field contains the number of seconds since the Link State advertisement originated. The Options field contains any IP Type of Service (TOS) features supported by the sending machine. The Link State Type identifies the type of link advertisement, using one of the values shown in Table 5.12. The value in the Link State Type field further defines the format of the advertisement.
|
Value |
Description |
|
1
|
Router links (router to area)
|
|
2
|
Network links (router to network)
|
|
3
|
Summary link (information on the IP network)
|
|
4
|
Summary link (information on autonomous system border router)
|
|
5
|
AS external link (external to autonomous system) |
The Link State ID field identifies which portion of the internetwork is described in the advertisement. The value depends on the Link State Type field and can contain IP addresses for networks or router IDs. The Advertising Router field identifies the originating router. The Link State Sequence Number is an incrementing number used to prevent old or duplicate packets from being interpreted. The Checksum field uses an IP algorithm for the entire message, including the header. Finally, the Length field contains the size of the advertisement, including the header.
HELLO Packets
Both types of OSPF headers are further encapsulated by the HELLO protocol, which is used for messaging between neighboring routers. The information in the HELLO header sets the parameters for the connection. The entire HELLO packet format is shown in Figure 5.15.
Figure 5.15. OSPF HELLO packet format.
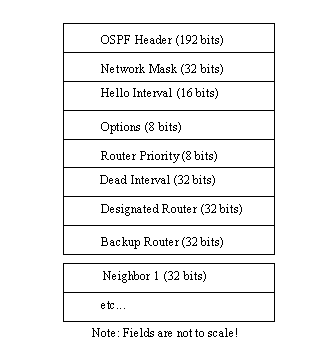{kind=link}
After the OSPF header is the Network Mask field, which is dependent on the interface. The Hello Interval is the number of seconds between subsequent Hello packets from the same router. The Options field is for IP's Type of Service supported values. The Router Priority field defines whether the router can be designated as a backup. If the field has a 0 value, the router cannot be defined as a backup. The Dead Interval is the number of seconds before a router is declared to be down and unavailable. The Designated and Backup Router fields hold the addresses of the designated and backup routers, if there are any. Finally, each neighbor has a set of fields that contain the address of each router that has recently (within the time specified by the Dead Interval) sent Hello packets over the network.
When this type of message is received by another router and it has been validated as containing no errors, the neighbor information can be processed into the neighbor data table.
Another message that is used to initialize the database of a router is the database description packet. It contains information about the topology of the network (either in whole or in part). To provide database description packet service, one router is set as the master, and the other is the slave. The master sends the database description packets, and the slave acknowledges them with database description responses.
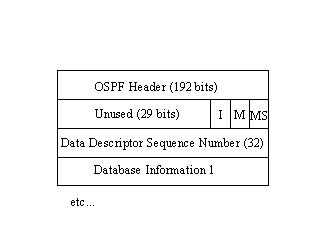
The format of the database description packet is shown in Figure 5.16. After the OSPF header is a set of unused bits, followed by three 1-bit flags. When the I (initial) bit is set to 0, it indicates that this packet is the first in a series of packets. The M (more) bit, when set to 1, means that more database description packets follow this one. The MS (master/slave) bit indicates the master/slave relationship. When it has a value of 1 it means that the router that sent the packet is the master. A 0 indicates that the sending machine is the slave. The Data Descriptor Sequence Number is an incrementing counter. The rest of the packet contains Link State advertisements as seen in Figure 5.14.
Figure 5.16. The database description packet layout.
{kind=link}
Link State Request and Update Packets
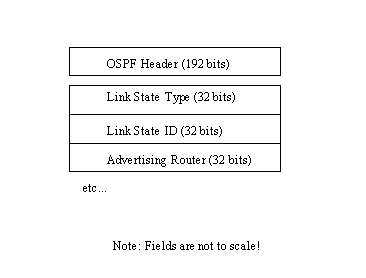
The Link State Request packet asks for information about a topological table from a database, whereas the Update packet can provide topological information of the types shown in Table 5.11. The Request packet is usually sent when an entry in the router's topological table is corrupted, missing, or out of date. The format of the Link State Request packet is shown in Figure 5.17. The Link State Request packet contains the OSPF header and a block of three repeating fields for the Link State Type, Link State ID, and Advertising Router.
Figure 5.17. OSPF Link State Request packet format.
{kind=link}
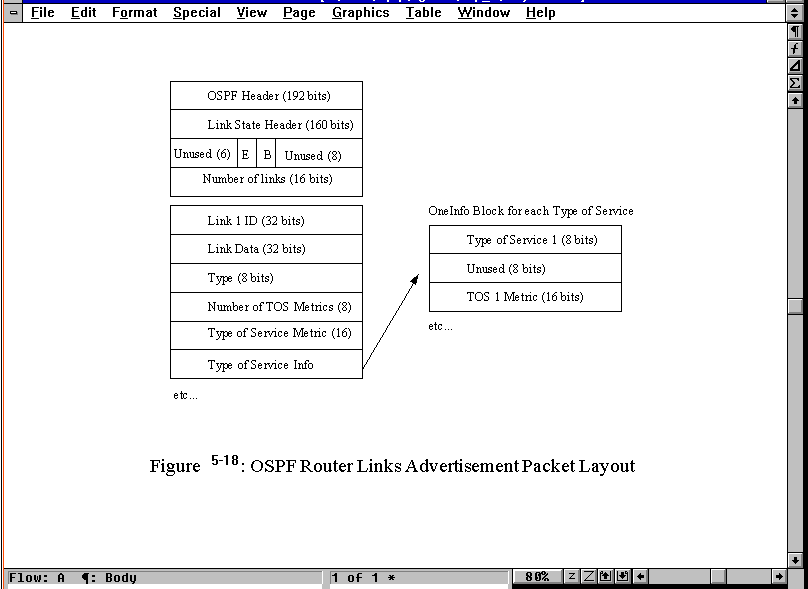
The Link State Update packet has four formats, depending on the link state type: router links, network links, summary links, or autonomous systems external links. The Router Links advertisement packet is sent to neighbors periodically and contains fields for each router link and the type of service provided in each link, as shown in Figure 5.18.
Figure 5.18. OSPF Router Links advertisement packet format.
{kind=link}
After the OSPF header and the Link State advertisement header are two single bit flags surrounded by 6- and 8-bit unused fields. The E (external) flag, when set to 1, indicates that the router is an autonomous systems (AS) boundary router. The B (border) flag, when set to 1, indicates that the router is an area border router. Following the unused 8-bit area is a field for the number of links (advertisements) in the message. Following this, the links are provided in sequence, one link to a block.
Each Link State advertisement block in the Router Links advertisement packet has a field for the Link ID (the type of router, although the value is dependent on the Type field later in the block), the Link Data (whose value is an IP address or a network mask, depending on the Type field's setting), the Type field (a value of 1 indicates a connection to another router, 2 a connection to a transit network, and 3 a connection to a stub network), and the Number of TOS field, which shows the number of metrics for the link (at least one must be provided, which is called TOS 0). Then, a repeating block is appended for each TOS, providing the type and the metric.
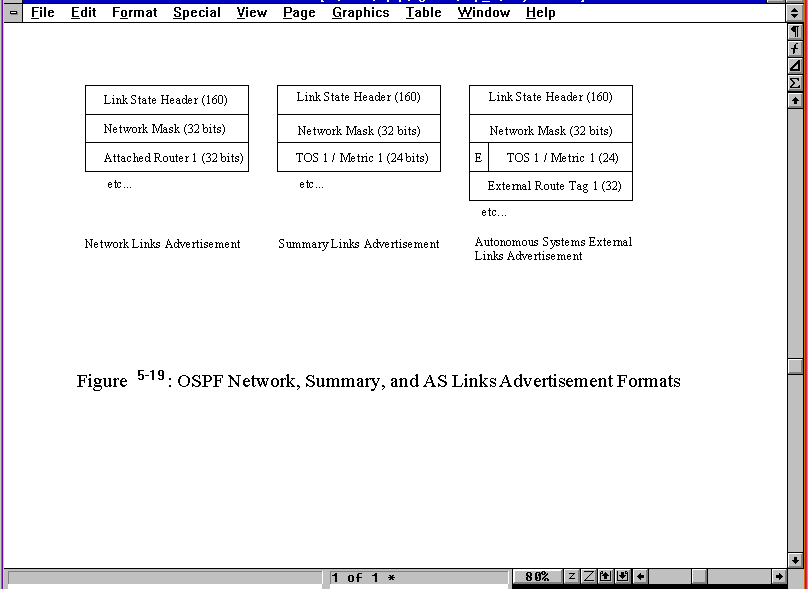
The other three formats available are the Network Links advertisement, Summary Links advertisement, and Autonomous Systems (AS) External Links advertisement. The formats of these advertisements are shown in Figure 5.19. The fields have all been described earlier in this section.
Figure 5.19. OSPF Network, Summary, and AS Links advertisement layouts.
{kind=link}
The last packet involved in OSPF is the Link State acknowledgment packet, which is required when a Link State advertisement has been received correctly. The layout of the acknowledgment packet is shown in Figure 5.20. The fields following the OSPF header are for the Link State Type, Link ID, Advertising Router ID, Link State Sequence Number, Link State Checksum value, and Link State Age, all of which have been mentioned earlier.
Figure 5.20. Link State acknowledgment packet layout.
{kind=link}
Summary
Today I looked at the gateway protocols used within the TCP/IP family specifically, as well as those in general use on the Internet and most networks. Gateways are a critical component for forwarding information from one network to another. Without gateways, each machine on the network would require a full map of every other machine on the internetwork.
As I have shown, there are several protocols of importance, depending on the role of the gateway. I also looked at the use of bridges, routers, and brouters in a network, and the role that each of these can play. With this material, I can leave the subject of gateways. Except for some message passing and administration material, you now know all you need about gateway protocols used with TCP/IP.
Q&A
What is a boundary gateway?
A boundary gateway sits between two networks within a larger internetwork, as would be found in a large corporation. The boundary gateways mark the edges (or boundaries) of each LAN, passing message to other LANs within the larger internetwork. Boundary gateways do not communicate with the networks outside the organization. This task is performed by exterior gateways.
How are sequence numbers used to control status messages within GGP? Explain for both the sending and receiving gateways.
The sending gateway sends packets with an incrementing sequence number. The destination gateway receives each packet and echoes back the sequence number in a message. If the destination gateway receives the next packet with a sequence number that does not follow the one last received, an error message is returned to the sender with the sequence number of the last packet in it. If the sequence number is correct, an acknowledgment is sent. As the sending gateway receives packets back from the destination, it compares the sequence number in the packet to its own internal counter. If the sequence number in the destination machine's packet does not match, the packet that would have been next in sequence from the last correctly received packet is resent.
What is a core gateway?
A core gateway is one that resides as an interface between a network and the internetwork. A non-core gateway is between two LANs that are not connected to the larger internetwork.
Protocol conversion takes place in which of the following: gateways, routers, bridges, or brouters?
Gateways perform protocol conversion. They have to because they can join two dissimilar network types. Some recent routers and brouters are capable of protocol conversion.
What are the three types of routing table?
Routing tables can be fixed (a table that is modified manually every time there is a change), dynamic (one that modifies itself based on network traffic), or fixed central (one downloaded at intervals from a central repository, which can be dynamic).
Quiz
- Define the role of gateways, routers, bridges, and brouters.
- What is a packet-switched network?
- What is the difference between interior and exterior neighbor gateways?
- What are the advantages and disadvantages of the three types of routing tables?
- What is the HELLO protocol used for?